Cubist
Building a symbolic autotelic agent: an AI that sets its own goals and learns its world as readable laws
The mission
Watch a child in a new place. Nobody hands them a goal or a reward function. They poke at things, notice what surprises them, invent little challenges, and out of that self-directed play comes an ever-growing repertoire of skills. Developmental AI researchers call such a learner autotelic, from the Greek auto (self) and telos (goal): an agent that invents, selects, and pursues its own goals, driven by curiosity rather than external reward (Oudeyer & Kaplan, 2007; Forestier et al., 2022; Colas et al., 2022).
Cubist's mission is to build one, with a twist. The autotelic agents of Oudeyer, Colas, and colleagues are usually powered by deep reinforcement learning. Cubist is symbolic all the way down. Its model of the world is a set of laws you can read. Its skills are small closed-loop programs. And the algorithm that improves both is a discrete cousin of gradient descent we call symbolic descent.
The bet: symbolic, not gradient
Almost everything that learns at scale today learns by gradient descent: nudge billions of opaque weights down a loss. It works spectacularly well when data is plentiful and the world holds still. But an agent dropped into a new world, learning from a single unfolding life, needs three things that gradients make expensive.
Continual learning. A neural network trained on something new tends to silently overwrite what it knew, the classic problem of catastrophic forgetting (McCloskey & Cohen, 1989). A theory made of discrete laws does not have that failure mode. A law that is already correct produces no error, and a learner driven by errors never touches it. One experience is enough to add a law, and adding it breaks nothing.
Reasoning. An explicit theory is something you can do things with: query it, plan through it, spot the exact situations it does not cover. Every law is a falsifiable claim. The world either behaves as the law says, or the law gets revised. A weight vector predicts; a theory explains.
Interpretability. When a symbolic model fails, the failure has an address: this condition was too narrow, that rule missed an entity. When it succeeds, the model is its own documentation.
To make this concrete, here is a real theory Cubist learned on one of the benchmark games, in about eight seconds of play:
# up key: the player (the only width-5 entity) moves 5 cells up
ACTION3: (self.width == 5) ⇒ move := (0, -5)
# down key: the same player moves 5 cells down
ACTION4: (self.width == 5) ⇒ move := (0, 5)
# right key: whatever sits on row 43 slides 5 cells right
ACTION2: (self.row == 43) ⇒ move := (5, 0)
# on every action, the entity with a direct neighbour (the life-bar)
# shifts its colours one notch: time is running out
any: exists(nbrs(d1)) ⇒ recolor := (0,0,0,2, 0,0,0,0, 0,0,0,-2, 0,0,0,0)
Four laws, and you know the game. Each one states when it fires, who it applies to, and what happens. When the world contradicts a law, that law and only that law is revised.
The honest counterpart: gradients win where perception is raw and data is abundant. The symbolic bet targets the opposite regime, low data, a single life, and a demand for explanations. That happens to be the regime children, robots in the field, and scientific discovery all live in.
The benchmark: ARC-AGI-3
Betting on a research direction means picking a test you cannot fool. Ours is ARC-AGI-3, the interactive-reasoning benchmark from the ARC Prize Foundation. The agent is dropped into a grid-world game with no instructions, no stated goal, and a handful of abstract actions, and must figure out what the game is while playing it. Scoring emphasizes sample efficiency: solving with fewer actions beats solving with more. That is Chollet's definition of intelligence as skill-acquisition efficiency made operational, and a benchmark where the goal is never stated is exactly the right exam for an agent whose whole premise is inventing goals for itself.
Where it stands
The world-model half is built and measured. Playing each of the 25 public ARC-AGI-3 games for a single 200-step life, with no pretraining, no gradients, and no game-specific tuning, Cubist learns each game's mechanics online as a small theory of laws, predicting every frame before learning from it. Held-out accuracy climbs from 0.46 in the first quarter of a run to 0.72 in the last, and 23 of 25 games end better than they started:
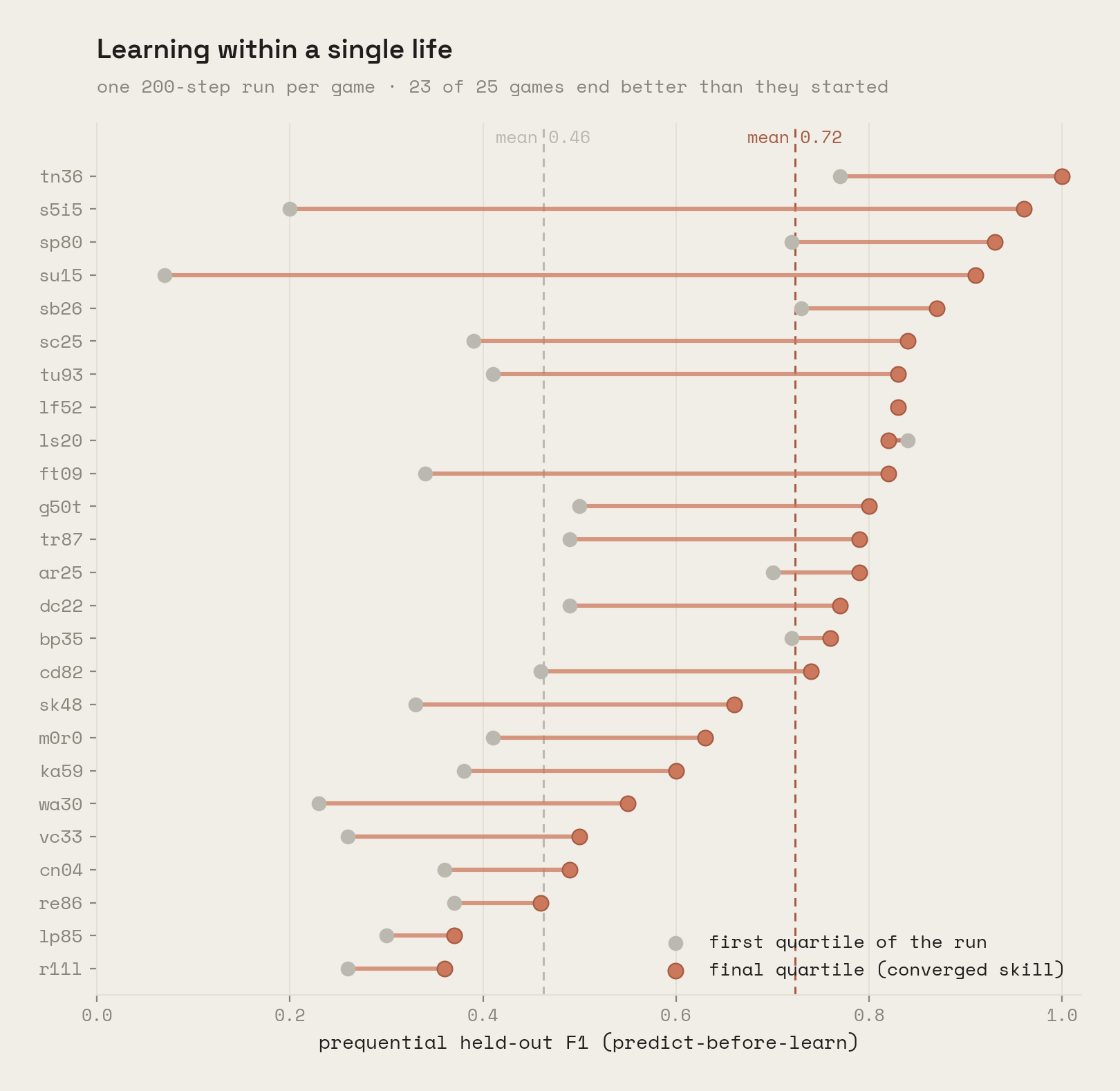
The results post covers the representation, the learning algorithm, every metric, and where the model breaks. The method post works through symbolic descent itself and the full parallel with gradient descent.
What's next: the autotelic loop
A model that predicts well is necessary but not sufficient. Prediction is not control, and on its own the world-model solves no levels. The second half of the program closes the loop:
- Gaps become goals. The model is honest: it never asserts a change it cannot justify, so its coverage gaps are a precise map of what is still unknown. That map is the agent's intrinsic motivation. Act where the theory is blind.
- Skills as programs. Behaviours are grown as closed-loop programs over the theory's own vocabulary, scored by imagining them forward through the world-model before spending a real action, and kept in an open-ended repertoire the way DreamCoder grows a library of reusable abstractions.
- The loop. Model the world, find what you cannot explain, invent a skill to probe it, and let the sharper model expose new gaps. Open-ended, self-directed, and readable at every step.
This is the part under active construction.
References
- Oudeyer & Kaplan (2007). What is intrinsic motivation? A typology of computational approaches. Frontiers in Neurorobotics.
- Colas, Karch, Sigaud & Oudeyer (2022). Autotelic agents with intrinsically motivated goal-conditioned reinforcement learning: a short survey. JAIR 74.
- Forestier, Portelas, Mollard & Oudeyer (2022). Intrinsically motivated goal exploration processes with automatic curriculum learning. JMLR 23(152).
- Chollet (2019). On the measure of intelligence.
- ARC Prize Foundation (2026). ARC-AGI-3: a new challenge for frontier agentic intelligence.
- Ellis et al. (2021). DreamCoder: bootstrapping inductive program synthesis with wake-sleep library learning. PLDI.
Writing
Laws from single experiences: an online symbolic world-model for ARC-AGI-3
Cubist's world-model learns each ARC-AGI-3 game's mechanics as a small theory of symbolic laws, online, from single experiences, with no pretraining and no gradients. This post presents the representation, the learning algorithm, and an evaluation across all 25 public games.
Symbolic descent: gradient descent, applied to rules instead of weights
Symbolic descent keeps the shape of gradient descent but changes the object it optimizes, from a weight vector to a readable theory of laws. This post explains the parallel, the machinery that makes it work, and what it buys for continual learning, reasoning, and interpretability.