Symbolic descent: gradient descent, applied to rules instead of weights
Symbolic descent keeps the shape of gradient descent but changes the object it optimizes, from a weight vector to a readable theory of laws. This post explains the parallel, the machinery that makes it work, and what it buys for continual learning, reasoning, and interpretability.
Louis Manhès
Founder & ML engineer
Cubist is an attempt to build a symbolic autotelic agent: one that sets its own goals and grows an open-ended repertoire of skills, in the tradition of intrinsically motivated agents (Colas et al., 2022), but with every moving part readable. An agent like that needs a very particular kind of learner. It must learn from single experiences, because a one-life world grants no replays. It must not forget, because every skill it builds tomorrow stands on what it learned today. And it must know what it does not know, because its own ignorance is the map it explores by.
Gradient descent, which nudges a vector of weights down a loss one small step at a time, is a poor fit for all three. It needs many passes to fit, it overwrites old competence when trained on new data, and a weight vector cannot point to the place where it is ignorant.
Symbolic descent keeps the shape of gradient descent and changes the object. Instead of a vector of weights, the thing being optimized is a small, readable theory: a set of typed laws. The claim of this post is that you can keep the whole machinery of gradient descent (loss, regularizer, gradient, mini-batch) and get something interpretable, stable under continual learning, and far more data-efficient in return. Cubist uses this to learn a world-model for ARC-AGI-3, but the method is general.
The correspondence
In parametric learning you minimize a loss L(θ) by stepping θ ← θ - η ∇L(θ). A regularizer biases toward simpler θ, a mini-batch estimates the gradient from a sample, and early stopping watches a held-out loss. Symbolic descent minimizes the same kind of objective, but θ is a structured discrete theory rather than a vector. Every familiar piece has a counterpart.
| gradient descent | symbolic descent |
|---|---|
| parameters: a weight vector | a theory: a set of typed laws |
| loss | the data cost (bits to encode the residual) |
| regularizer | the model cost (bits to write the laws; Occam, built in) |
| the gradient | the labelled errors (miss, over-fire, true delta) |
| the space of descent directions | the abduction set: every small program that explains the error |
| a gradient step | a directed edit (generalize, specialize, or patch) |
| a mini-batch | the revised laws' own support: every past transition they answer for |
| early stopping on validation loss | held-out, predict-before-learn scoring |
| weight decay | condensation: merging laws whenever the merged theory costs fewer bits |
| a convex bowl | a combinatorial lattice with real local minima |
The objective is a two-part description length, L(T) + L(D | T): the bits to write the theory down, plus the bits to encode the data given it, paid wherever the theory mispredicts (Rissanen, 1978). The two terms are loss and regularizer at once, which is the quiet but important part. A law earns its place if and only if it saves more bits in the residual than it costs to write. There is no precision threshold, no minimum-support count, nothing to tune. The bits decide.
Errors are the gradient, abduction is the direction set
This is the load-bearing row of the table. A gradient tells you the direction in which a continuous loss falls fastest. In symbolic descent, the labelled prediction errors tell you exactly which edits can lower the description length. They do more than a gradient does, because they are labelled.
The mechanism is abduction. For every observed change the model failed to explain, it enumerates every small expression that exactly computes that change: constants, attribute reads off the entity, reads off a unique neighbour, and one or two arithmetic combinations of these. This abduction set is the space of possible explanations for the change, the discrete counterpart of the candidate descent directions. It turns learning into set algebra:
- Same regime = intersection. Two changes belong to the same law when their abduction sets overlap. There is no clustering metric and no
kto choose. If a small program explains both, they are one behaviour. - Generalize = anti-unify. Two laws merge by keeping their shared structure and lifting clashing constants into computed expressions.
colour == 3andcolour == 5becomecolour == the(touching).colourwhen that expression sits in both abduction sets. This is the bottom-clause generalization of inductive logic programming (Muggleton, 1995), run online. - Memorize = the guaranteed floor. The literal change is always in the abduction set, so the model can always patch a change it cannot yet name. This is deliberate memorization, honestly accounted: a patch is expensive in bits, which is precisely the pressure to replace it with structure later.
A worked step makes it concrete. Suppose a law moves every red entity three cells up, and it fires correctly. Now a green entity moves the same way under the same action, and no law covers it: one miss. The green entity's abduction set contains move := (0, -3); so does the red law's. Non-empty intersection: same regime. Anti-unification drops the colour condition, and the merged law covers both. The model cost falls because one condition is gone, the data cost falls because the green move is now explained, and no red entity is disturbed. One labelled miss has moved the theory exactly one step downhill.
Weight decay that actually deletes
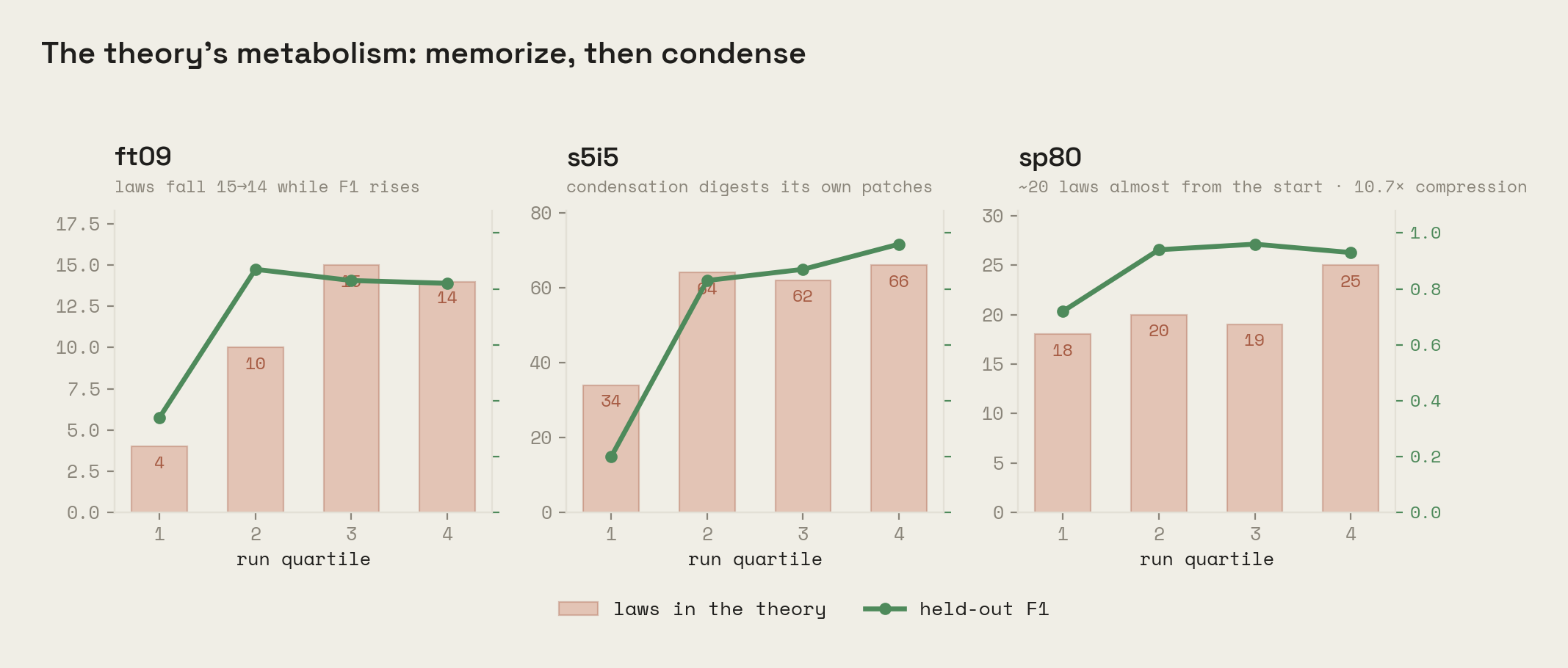
Gradient descent shrinks weights toward zero; symbolic descent has something better. Condensation sweeps the theory for pairs of laws that share an explanation and merges them whenever the merged theory costs fewer bits, best saving first, until nothing improves. Patches dissolve into laws as evidence accumulates, and the theory loses laws while gaining accuracy. In our benchmark you can watch it happen: on game ft09 the law count falls from 15 to 14 across the run while held-out accuracy rises, and roughly one revision in three across all 25 games ends with fewer, broader laws than it started with.
What the method buys
The parallel is pretty, but the reason to care is what comes out of it. Each claim below is a measured number, not an aspiration (full protocol in the results post).
Continual learning without catastrophic forgetting. Each revision touches exactly the laws implicated by the error, re-fit over their own support: every past transition they answer for. A law that is already correct produces no error, and the descent never disturbs it. Learning something new therefore has no way to silently break something old, the failure mode that has haunted connectionist learners since McCloskey & Cohen (1989). Measured: across ~2,700 revisions over 25 games, only 18 revisions lost any accuracy on their laws' own past, a 0.7% regression rate.
Generalization instead of memorization, and you can read the margin. Because the model cost is real bits, a law that merely stores what it has seen is expensive and loses to one that compresses. The objective actively prefers the general law over the lookup table, and the margin is a single number: the compression ratio, bits of data explained per bit of theory. Eight of 25 games end above 1.0, meaning genuine structure, topping out at 10.7×: a game's whole visible dynamics in about twenty falsifiable sentences. Games below 1.0 are memorization-heavy, and the number says so rather than hiding it.
Data efficiency. A single informative experience justifies a single edit, applied immediately: the model is exact on the frame it just erred on. There is no batch to accumulate and no epoch to re-run, which is exactly the resource a one-life, learn-while-playing setting denies a network.
Interpretability and honest uncertainty. The parameter is a list of laws you can read, so every prediction traces to the law that produced it, and every failure decomposes into the component that blocked it: a gate, a selector, a transform. And what no law explains is left unchanged rather than guessed, so the model's silence is a real coverage gap. That is the very signal an autotelic agent turns into a goal.
Where the analogy bites
It is a lens, not an identity. There is no continuous gradient: the space is discrete, so "the gradient" is really the finite set of abducible edits and their cost differences, and the step is the argmin over that set. The terrain is a combinatorial lattice with real local minima, where a smooth convex loss has none, so a misleading early edit can trap the descent. The honest framing is directed discrete local search, but one whose direction set is constructed from the data by abduction, not sampled blindly the way evolutionary methods probe fitness.
The parametric toolbox still transfers. The model cost is already a complexity penalty, and richer priors slot in the same way. Beams, restarts, and annealing are drop-in optimizers. The replay reservoir is the mini-batch, and held-out predict-before-learn scoring is early stopping.
Related work
Symbolic descent sits at the intersection of several traditions. Inductive logic programming supplies the bones: per-entity most-specific descriptions are Progol-style bottom clauses (Muggleton, 1995), generalized by contrast against negatives. Theory induction framings share the laws-as-programs stance: the Apperception Engine (Evans et al., 2020), Schema Networks (Kansky et al., 2017), and the recent program-synthesis world-models WorldCoder and PoE-World. The salient difference: those recent systems use an LLM to propose the programs, where symbolic descent learns fully online, without an LLM proposer, from single transitions. The same contrast holds against LLM coding-agent approaches to ARC-AGI-3 (Rodionov, 2026). State-merging automata induction (RPNI: Oncina & García, 1992; ALERGIA: Carrasco & Oncina, 1994) is the direct ancestor of condensation: start from total memorization, merge while a description-length criterion pays. And DreamCoder's wake-sleep library learning is the closest relative of what comes next for Cubist: growing a repertoire of skills by the same compression pressure that grows the laws.
The point of all this is not a clever analogy. It is that an agent meant to learn continually, and to set its own goals, needs a learner that does not forget, generalizes from little data, and knows what it does not know. Symbolic descent is an attempt at exactly that learner. The companion post puts it to work as a world-model across all 25 public ARC-AGI-3 games and reports how well it does, curves, tables, and failures included.
References
- Muggleton (1995). Inverse entailment and Progol. New Generation Computing 13.
- Rissanen (1978). Modeling by shortest data description. Automatica 14.
- McCloskey & Cohen (1989). Catastrophic interference in connectionist networks. Psychology of Learning and Motivation 24.
- Oncina & García (1992). Inferring regular languages in polynomial updated time (RPNI). Carrasco & Oncina (1994). Learning stochastic regular grammars by means of a state merging method (ALERGIA).
- Evans et al. (2020). Making sense of sensory input (the Apperception Engine).
- Kansky et al. (2017). Schema Networks: zero-shot transfer with a generative causal model of intuitive physics. ICML.
- Tang, Key & Ellis (2024). WorldCoder: building world models by writing code and interacting with the environment. NeurIPS.
- Piriyakulkij et al. (2025). PoE-World: compositional world modeling with products of programmatic experts. NeurIPS.
- Rodionov (2026). Executable world models for ARC-AGI-3 in the era of coding agents.
- Ellis et al. (2021). DreamCoder: bootstrapping inductive program synthesis with wake-sleep library learning. PLDI.
- Colas, Karch, Sigaud & Oudeyer (2022). Autotelic agents with intrinsically motivated goal-conditioned reinforcement learning: a short survey. JAIR 74.