Laws from single experiences: an online symbolic world-model for ARC-AGI-3
Cubist's world-model learns each ARC-AGI-3 game's mechanics as a small theory of symbolic laws, online, from single experiences, with no pretraining and no gradients. This post presents the representation, the learning algorithm, and an evaluation across all 25 public games.
Louis Manhès
Founder & ML engineer
Cubist is building an agent for ARC-AGI-3 that learns each game's mechanics as a small theory of symbolic laws, online, from single experiences, with no pretraining and no gradients. This post presents the world-model half of that effort: the representation, the learning algorithm, and an evaluation across all 25 public games. The learning algorithm itself, symbolic descent, has its own post.
The theory a game produces is human-readable. Here is a real one, learned in eight seconds of play:
# up key: the player (the only width-5 entity) moves 5 cells up
ACTION3: (self.width == 5) ⇒ move := (0, -5)
# down key: the same player moves 5 cells down
ACTION4: (self.width == 5) ⇒ move := (0, 5)
# right key: whatever sits on row 43 slides 5 cells right
ACTION2: (self.row == 43) ⇒ move := (5, 0)
# on every action, the entity with a direct neighbour (the life-bar)
# shifts its colours one notch: time is running out
any: exists(nbrs(d1)) ⇒ recolor := (0,0,0,2, 0,0,0,0, 0,0,0,-2, 0,0,0,0)
That is the movement system of the game ls20, inferred from about thirty frames, and every law in it is a falsifiable claim the model keeps revising as evidence arrives.
ARC-AGI-3
ARC-AGI-3 is the interactive-reasoning benchmark from the ARC Prize Foundation (technical report). An agent is dropped into a grid-world game of 16-colour frames, with an action space of up to five abstract keys plus a pixel click, and must figure out what the game is while playing it. The goal is never stated; the mechanics must be inferred, tested, and exploited, level by level. The public release ships 25 games spanning three interface families: keyboard-driven movement puzzles, click-driven games of buttons and cascades, and mixed ones. Scoring emphasizes sample efficiency: solving with fewer actions beats solving with more, which is Chollet's skill-acquisition-efficiency view of intelligence made operational. It is precisely the regime where learning explicit structure should pay.
Why a symbolic world-model
Three properties we want that gradient world-models make expensive:
- One-shot revision. A game reveals a mechanic once; the model should account for it now, not after a thousand replays. Our learner revises its theory on every prediction error and is exact on the revised frame immediately.
- Verifiable exactness. A symbolic law either reproduces an observed transition or it does not. There is no soft loss to hide behind, so the evaluation can demand that the theory explain every frame it was fit on, and can measure regression when an edit forgets the past.
- Legibility. The theory is the explanation. When the model fails, the failure can be attributed to the component that caused it, and that attribution points to the next improvement.
We are explicit about what a world-model does not buy: prediction is not control. A model can predict a game well and still not solve it. Reward and planning are separate problems, and this post is about the modeling half.
Related work
Our approach sits at the intersection of several traditions. Inductive logic programming supplies the bones: our per-entity most-specific descriptions are Progol-style bottom clauses (Muggleton, 1995), generalized by contrast against negatives. Theory induction framings share our laws-as-programs stance: the Apperception Engine (Evans et al., 2020), Schema Networks (Kansky et al., 2017), and the recent program-synthesis world-models PoE-World and WorldCoder. We differ in learning fully online, without an LLM proposer, from single transitions, a contrast that also holds against LLM coding-agent systems for ARC-AGI-3 itself (Rodionov, 2026). State-merging automata induction (RPNI: Oncina & García, 1992; ALERGIA: Carrasco & Oncina, 1994) is the direct ancestor of our condensation step: start from total memorization, merge while a description-length criterion pays. And MDL (Rissanen, 1978) is the single objective throughout. A law earns its bits or it does not exist.
Method
Perception. Each frame is segmented into tracked, object-centric entities carrying position, size, a colour histogram, their own velocity, and a local relation graph to their neighbours. Consecutive frames yield a transition: per-entity changes on three axes (move, resize, recolor), each change a fact the model must explain.
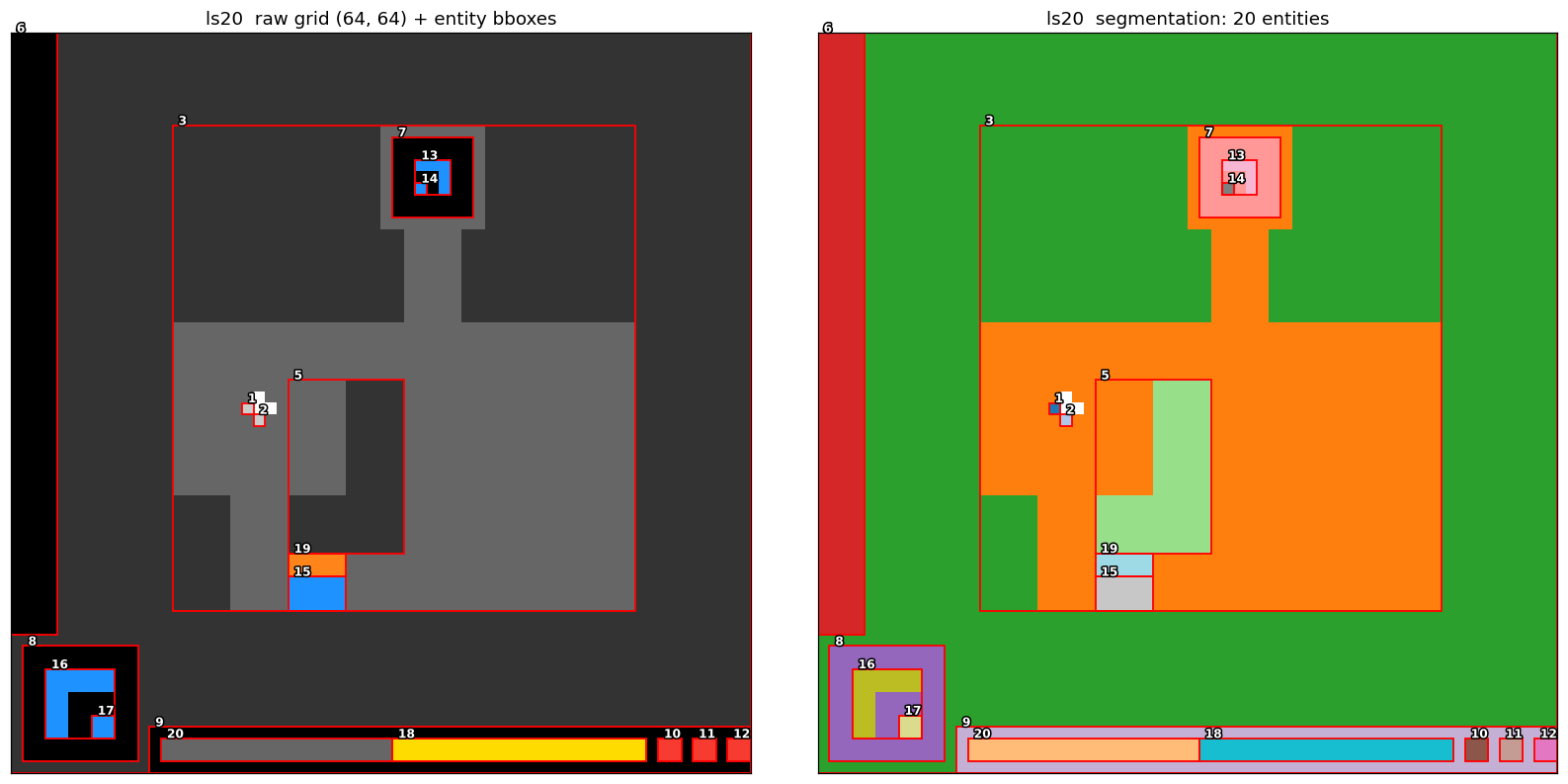
Laws. Laws are written in a typed expression language over the scene graph: attribute reads, neighbour traversal, aggregation, arithmetic, comparison, and the click. A law has four parts:
(action?, focus?, selector, transforms)
Under a given action, if the clicked entity matches the focus condition, then every entity matching the selector (the who) undergoes every transform (the what). One law can speak to several axes at once, because entities overwhelmingly change several axes together.
Abduction. For every observed change, the learner enumerates every small expression that exactly computes it: constants, attribute reads off the entity, off the clicked entity, or off a unique neighbour, and one or two arithmetic combinations of these. This abduction set is the change's space of possible explanations, and it converts learning into set operations. Two changes obey the same law when their abduction sets intersect. Two laws generalize by anti-unification, keeping their shared structure and lifting clashing constants into computed expressions such as colour == the(touching).colour. And the literal change is always present as a fallback, so the model can memorize what it cannot yet explain.
Fitting. The learner groups changes by shared explanation, takes the largest group still unexplained, and names it: it searches for the cheapest selector that admits the group and excludes every entity that stayed still or changed differently, growing the condition step by step and validating against counterexamples. Whatever no selector can name is patched with per-entity memorized laws. Finally, condensation merges laws that share an explanation whenever the merge saves description length, so patches dissolve into general laws as evidence accumulates. At every stage the theory remains exact on the data it was fit on.
The online loop. At every step the model predicts the incoming transition before learning from it. That prediction is the honest held-out score, one point of a learning curve. On any error, the model revises exactly the laws implicated by the error, refitting them over every past transition they answer for. Laws that remain general and consistent pass through untouched. The revision must explain the new transition while keeping the past, and both halves are measured at every step.
Evaluation protocol
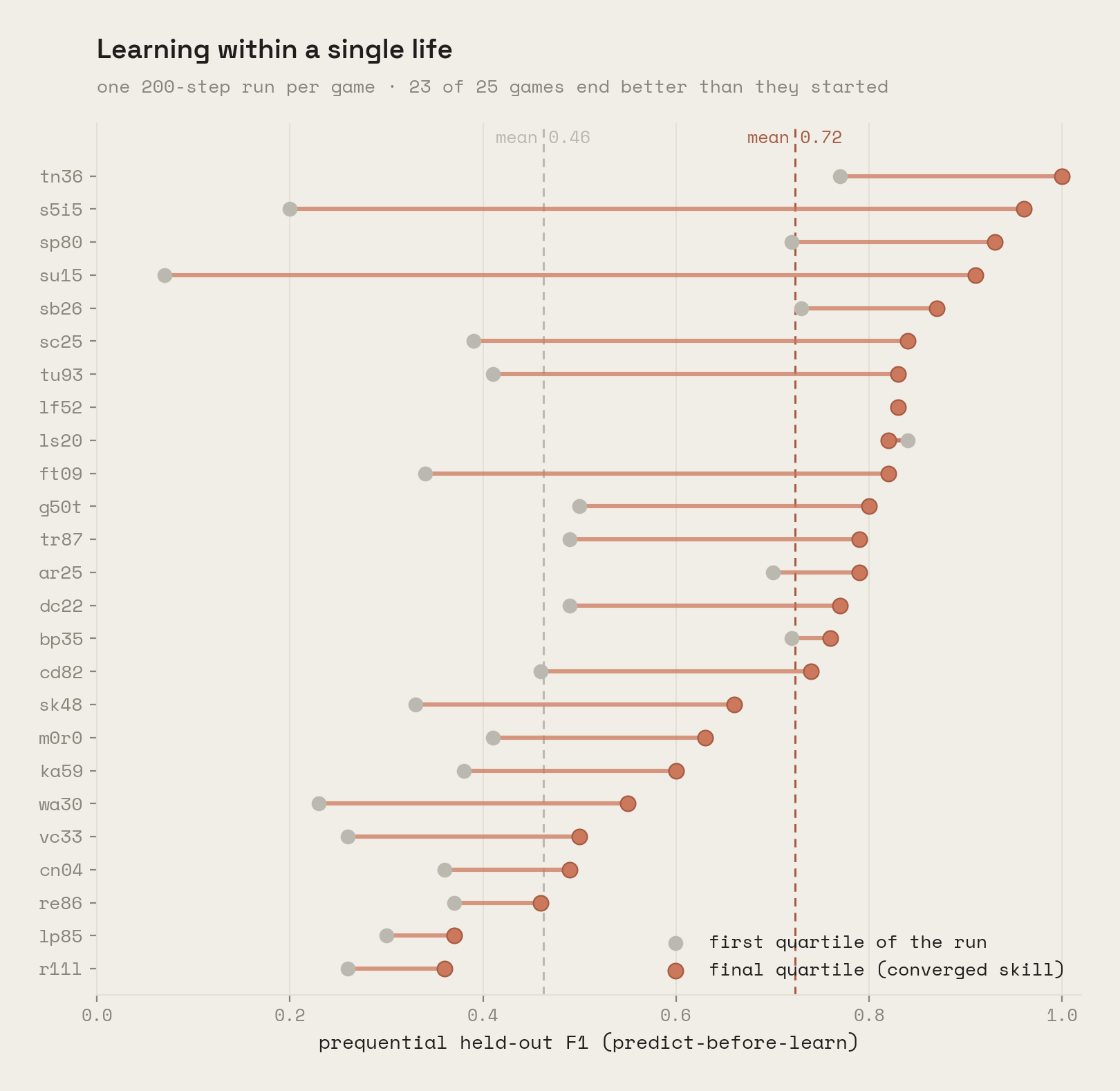
Each of the 25 public games is played for a single 200-step life under a uniformly random policy, with one shared configuration and no per-game tuning. We report:
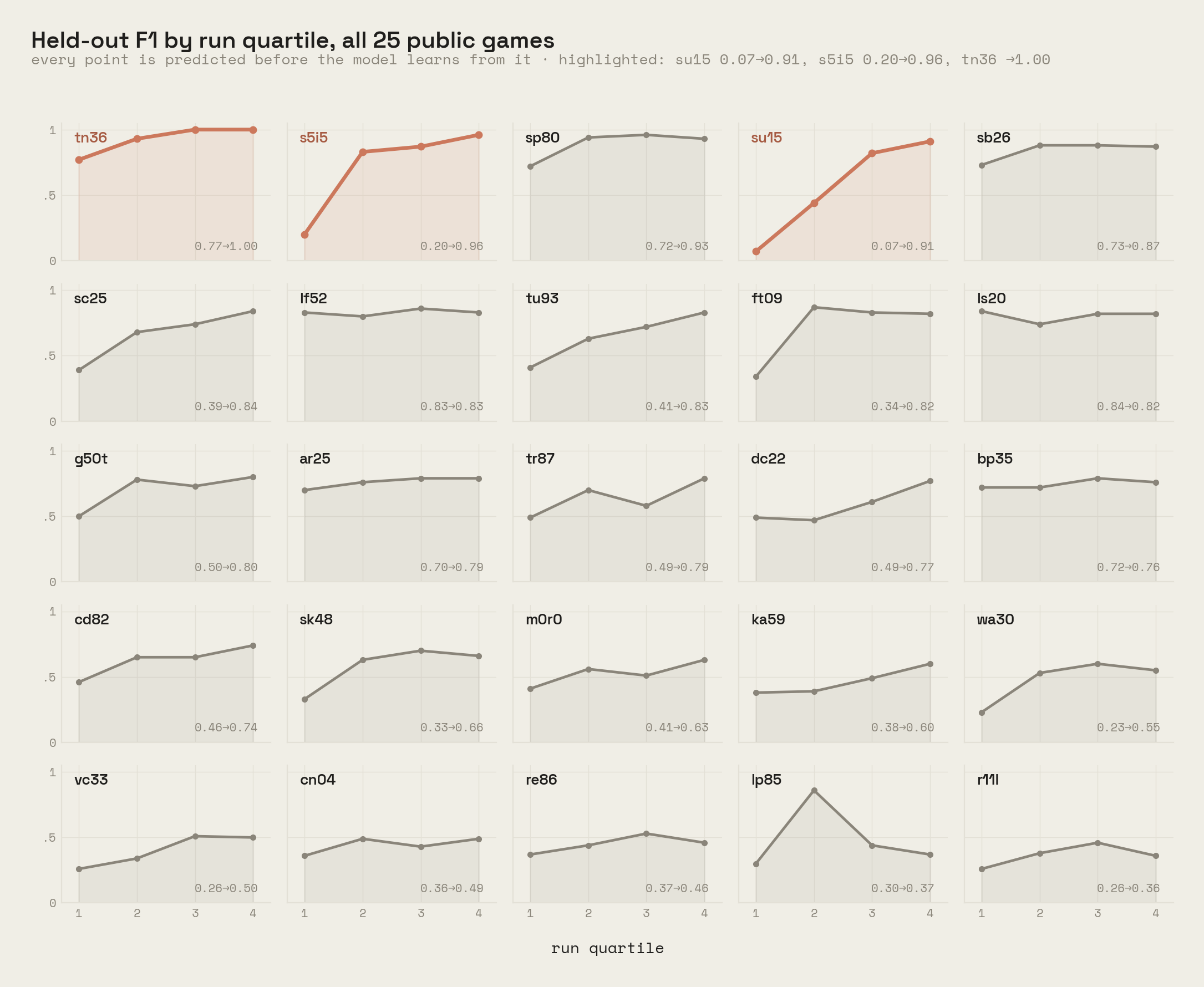
- F1, the prediction quality. Every transition is predicted by the theory fit on transitions 1 to t−1, before the model learns from it (prequential scoring), so every number is held out by construction. We summarize by run quartile, because prediction is a curve, not a number.
- Revisions, how often the theory had to change. A revision happens only when a prediction erred.
- Regressions, revisions that lost accuracy on past transitions the edited laws covered. This is the continual-learning claim under test.
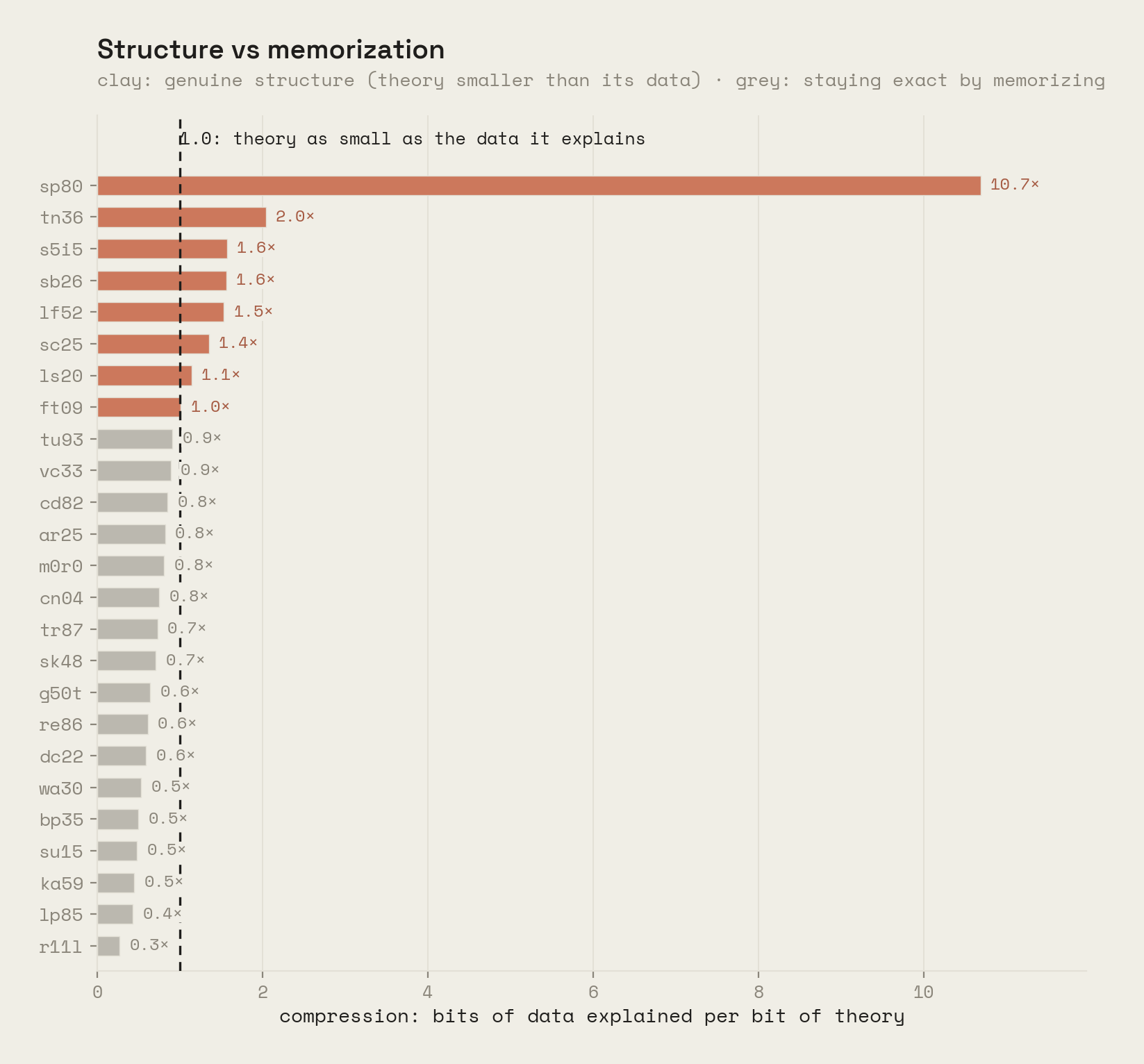
- Compression, bits of data the theory explains per bit of theory. Above 1, the theory is smaller than the data it reproduces and has genuinely generalized; below 1, it is staying exact by memorizing.
- Coverage, the fraction of all past changes the final theory reproduces exactly. The distance between coverage and F1 is the generalization gap, measured rather than assumed.
Results
| game | F1 | F1 (Q1→Q4) | revisions | regressions | laws | compression | coverage |
|---|---|---|---|---|---|---|---|
| tn36 | 0.93 | 0.77→1.00 | 63 | 1 | 93 | 2.0 | 1.00 |
| sp80 | 0.89 | 0.72→0.93 | 34 | 0 | 23 | 10.7 | 0.92 |
| sb26 | 0.84 | 0.73→0.87 | 43 | 0 | 43 | 1.6 | 1.00 |
| lf52 | 0.83 | 0.83→0.83 | 134 | 0 | 98 | 1.5 | 1.00 |
| ls20 | 0.81 | 0.84→0.82 | 79 | 0 | 80 | 1.1 | 0.93 |
| ar25 | 0.76 | 0.70→0.79 | 111 | 0 | 120 | 0.8 | 0.99 |
| bp35 | 0.75 | 0.72→0.76 | 154 | 0 | 302 | 0.5 | 1.00 |
| ft09 | 0.73 | 0.34→0.82 | 23 | 0 | 24 | 1.0 | 1.00 |
| s5i5 | 0.72 | 0.20→0.96 | 75 | 1 | 63 | 1.6 | 0.98 |
| g50t | 0.71 | 0.50→0.80 | 112 | 0 | 122 | 0.6 | 0.96 |
| sc25 | 0.66 | 0.39→0.84 | 120 | 0 | 130 | 1.4 | 0.99 |
| tu93 | 0.65 | 0.41→0.83 | 122 | 0 | 148 | 0.9 | 0.93 |
| tr87 | 0.64 | 0.49→0.79 | 140 | 2 | 112 | 0.7 | 0.95 |
| cd82 | 0.63 | 0.46→0.74 | 112 | 0 | 116 | 0.9 | 1.00 |
| dc22 | 0.59 | 0.49→0.77 | 127 | 0 | 140 | 0.6 | 0.95 |
| sk48 | 0.57 | 0.33→0.66 | 139 | 1 | 306 | 0.7 | 0.99 |
| su15 | 0.56 | 0.07→0.91 | 37 | 0 | 25 | 0.5 | 1.00 |
| m0r0 | 0.53 | 0.41→0.63 | 122 | 0 | 160 | 0.8 | 0.98 |
| lp85 | 0.50 | 0.30→0.37 | 14 | 3 | 85 | 0.4 | 0.71 |
| wa30 | 0.47 | 0.23→0.55 | 125 | 0 | 119 | 0.5 | 0.97 |
| ka59 | 0.47 | 0.38→0.60 | 154 | 4 | 193 | 0.5 | 0.94 |
| re86 | 0.45 | 0.37→0.46 | 187 | 0 | 236 | 0.6 | 0.99 |
| cn04 | 0.44 | 0.36→0.49 | 139 | 0 | 144 | 0.8 | 0.97 |
| vc33 | 0.40 | 0.26→0.50 | 175 | 3 | 146 | 0.9 | 0.92 |
| r11l | 0.37 | 0.26→0.36 | 183 | 3 | 470 | 0.3 | 0.96 |
The theory learns without forgetting. Across roughly 2,700 revisions in 25 games, the theory always ends up explaining the frame it just erred on, and revisions that lost accuracy on the past total 18, a 0.7% rate. Generalization is not aspirational either: over 900 revisions, roughly one in three, ended with fewer and broader laws than they started with.
The headline is the curve, not the mean. A whole-run average penalizes the model for having once been ignorant: at step one it knows nothing by construction, and every early error drags the mean down. Since every point is held out, the honest estimate of converged skill is the final quartile. There, the aggregate reads 0.46 in the first quartile against 0.72 in the last, with 23 of 25 games ending better than they started (one flat; the one decline, ls20, starts at its ceiling of 0.84). The standouts read like learning should: su15 climbs from 0.07 to 0.91 within a single 200-step run, s5i5 from 0.20 to 0.96, and tn36 reaches a perfect 1.00 held-out F1 over its final hundred steps. Where a curve dips mid-run (lp85, late sk48), the cause is visible in the data: a level transition changed the mechanics, and the theory paid to re-learn them.
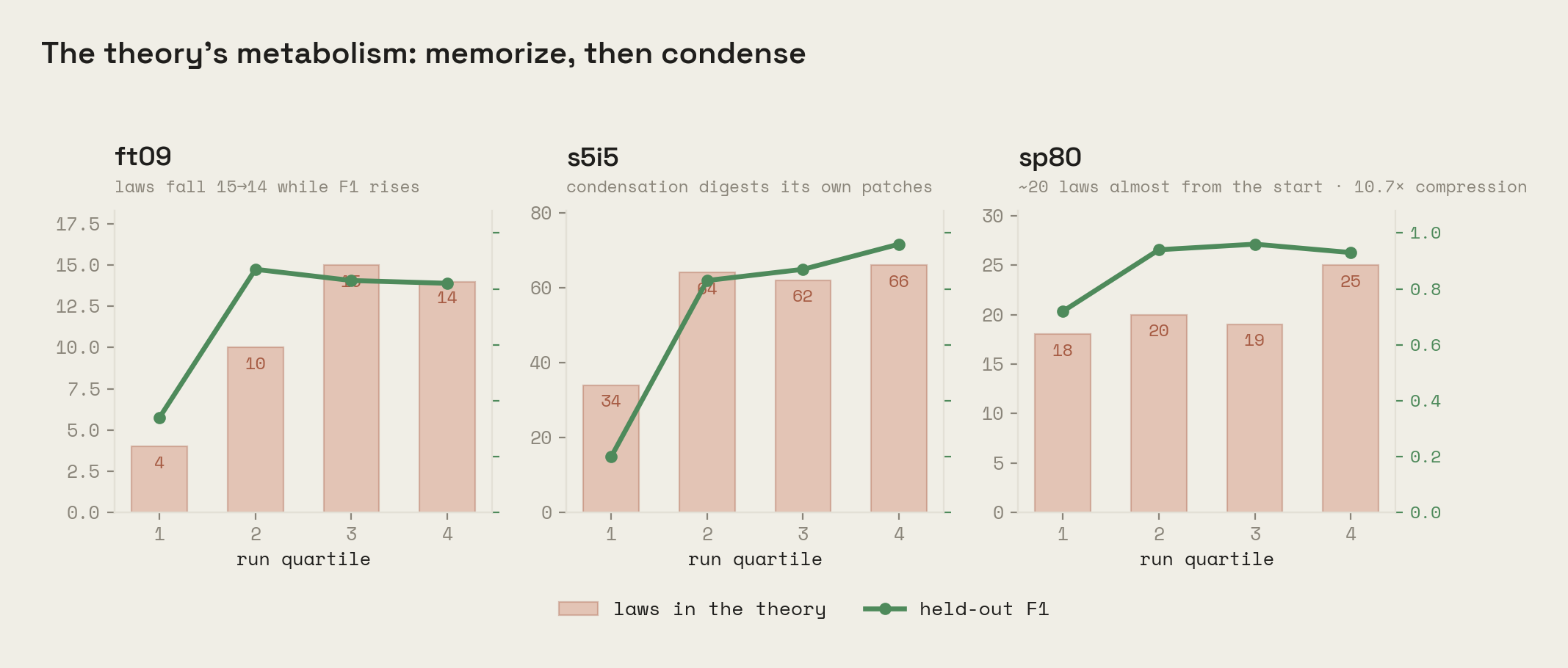
The theory has a metabolism. Theory size mostly grows as experience accumulates, but watch ft09 (15 laws down to 14) and s5i5 (64 down to 62): the count falling while F1 rises is condensation digesting its own memorized patches into broader laws. sp80 is the other extreme, holding about twenty laws essentially from the start with a compression of 10.7×. The game's whole visible dynamics fit in twenty falsifiable sentences.
Prediction is held out; coverage is not. Read the two columns together: a final-quartile F1 of 0.72 against a coverage around 0.96. The theory almost always explains its past, and the remaining distance to its one-step-ahead predictions is the generalization gap, measured per game rather than assumed.
Where the structure is real. Eight games end with compression at or above 1.0, meaning the theory is smaller than the data it reproduces, topping out at 10.7× (sp80) and 2.0× (tn36). Games below 1.0 are memorization-heavy: the model stays exact by patching what it cannot yet name, and says so.
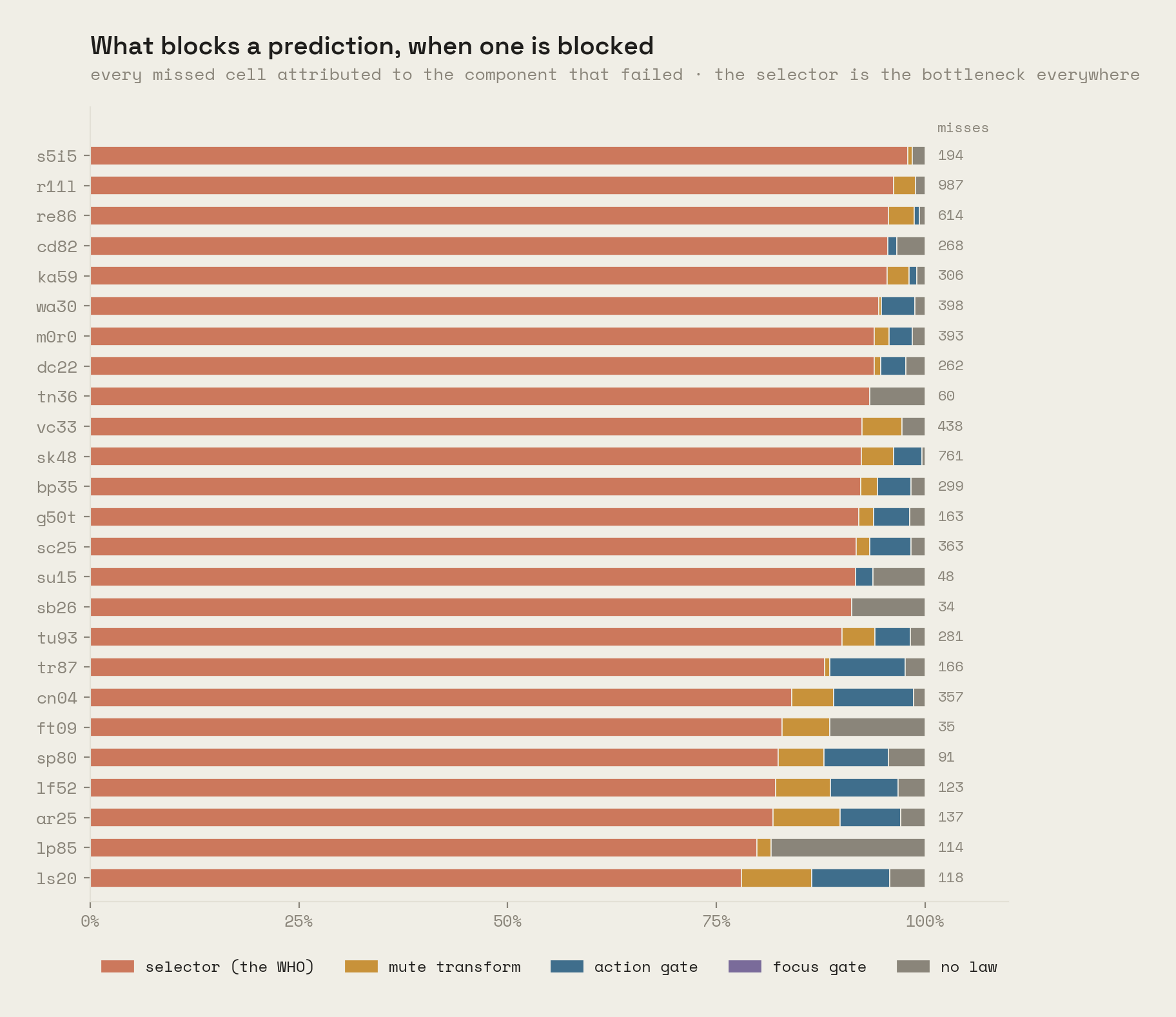
Where it struggles. Because every miss can be attributed to the component that blocked it, the diagnosis is unambiguous: on every hard game the blocking component is the selector, the part of a law that decides who it applies to (950 of r11l's misses, 703 of sk48's). The laws that would predict these changes exist; their selectors fail to extend to entities they have not seen. That is the single sharpest open problem this evaluation isolates. A smaller, separate residue is genuine ambiguity: on a few games (105 cells on vc33, 46 on lp85), entities with identical observable context behave differently, which no selector over observable attributes can separate. The model reports these rather than averaging them away.
Limitations
Prediction is not control. Nothing here selects actions; the driver is uniformly random, and when it clears a level anyway that is luck, not competence. A policy that exploits the theory is the next milestone, the autotelic half of the program, and prior experiments warn us the coupling is not free.
Existence is unmodeled. Entities that appear or vanish fall outside the three axes. This is a known, deferred fourth axis.
Ambiguity is real. On some games, entities with identical observable context behave differently. No selector over observable attributes can separate them, and the model counts them honestly rather than averaging them away.
Cost grows with history. Revising a law over everything it has ever explained is what keeps the no-forgetting guarantee, but it makes the busiest games expensive. Bounding that growth without giving up the guarantee is the main open question on the engineering side.
We would rather publish a small model whose every claim is checkable than a large one whose failures are invisible. Every number in this post comes from one shared configuration, and every prediction was made before the model saw the answer.
References
- ARC Prize Foundation (2026). ARC-AGI-3: a new challenge for frontier agentic intelligence. Benchmark: arcprize.org/arc-agi/3.
- Chollet (2019). On the measure of intelligence.
- Muggleton (1995). Inverse entailment and Progol. New Generation Computing 13.
- Evans et al. (2020). Making sense of sensory input (the Apperception Engine).
- Kansky et al. (2017). Schema Networks: zero-shot transfer with a generative causal model of intuitive physics. ICML.
- Piriyakulkij et al. (2025). PoE-World: compositional world modeling with products of programmatic experts. NeurIPS.
- Tang, Key & Ellis (2024). WorldCoder: building world models by writing code and interacting with the environment. NeurIPS.
- Rodionov (2026). Executable world models for ARC-AGI-3 in the era of coding agents.
- Rissanen (1978). Modeling by shortest data description. Automatica 14.
- Oncina & García (1992). Inferring regular languages in polynomial updated time (RPNI). Carrasco & Oncina (1994). Learning stochastic regular grammars by means of a state merging method (ALERGIA).